Curso IA
Bloque 2 · Aprendizaje
Cómo aprenden las máquinas (sin lenguaje todavía)
En el Bloque 1 hemos puesto las bases: ya sabemos qué es la inteligencia artificial, qué no es, por qué no piensa ni comprende como un ser humano y qué tipo de inteligencia estamos usando realmente hoy. Con ese marco claro, ahora toca dar el siguiente paso lógico: entender cómo una máquina puede comportarse de forma razonable sin que le escribamos todas las reglas.
Este bloque aborda el cambio más importante de la IA moderna: el paso de programar instrucciones detalladas a permitir que el sistema ajuste su comportamiento a partir de resultados. No entramos todavía en lenguaje, texto ni modelos concretos. El objetivo aquí es comprender el principio de aprendizaje, no su implementación técnica. Qué significa aprender para una máquina, en qué se diferencia radicalmente del aprendizaje humano y por qué este enfoque hace posible resolver problemas que antes eran inabordables.
A lo largo de estos capítulos verás cómo se redefine el papel del ser humano: dejamos de intentar anticipar todos los casos posibles y pasamos a definir objetivos, criterios de éxito y marcos de ajuste. También entenderás por qué los datos se convierten en un elemento central, cómo guían el comportamiento de la IA y por qué condicionan tanto sus capacidades como sus límites.
Este bloque es clave porque elimina muchas confusiones habituales: la idea de que la máquina “entiende”, de que aprende como una persona o de que el código lo es todo. Al terminarlo, tendrás una visión clara, sobria y realista de qué significa aprender en una máquina y por qué este enfoque ha cambiado para siempre la forma de construir sistemas inteligentes.


CAPÍTULO 6
El cambio clave: de programar reglas a aprender de datos
Resumen del capítulo
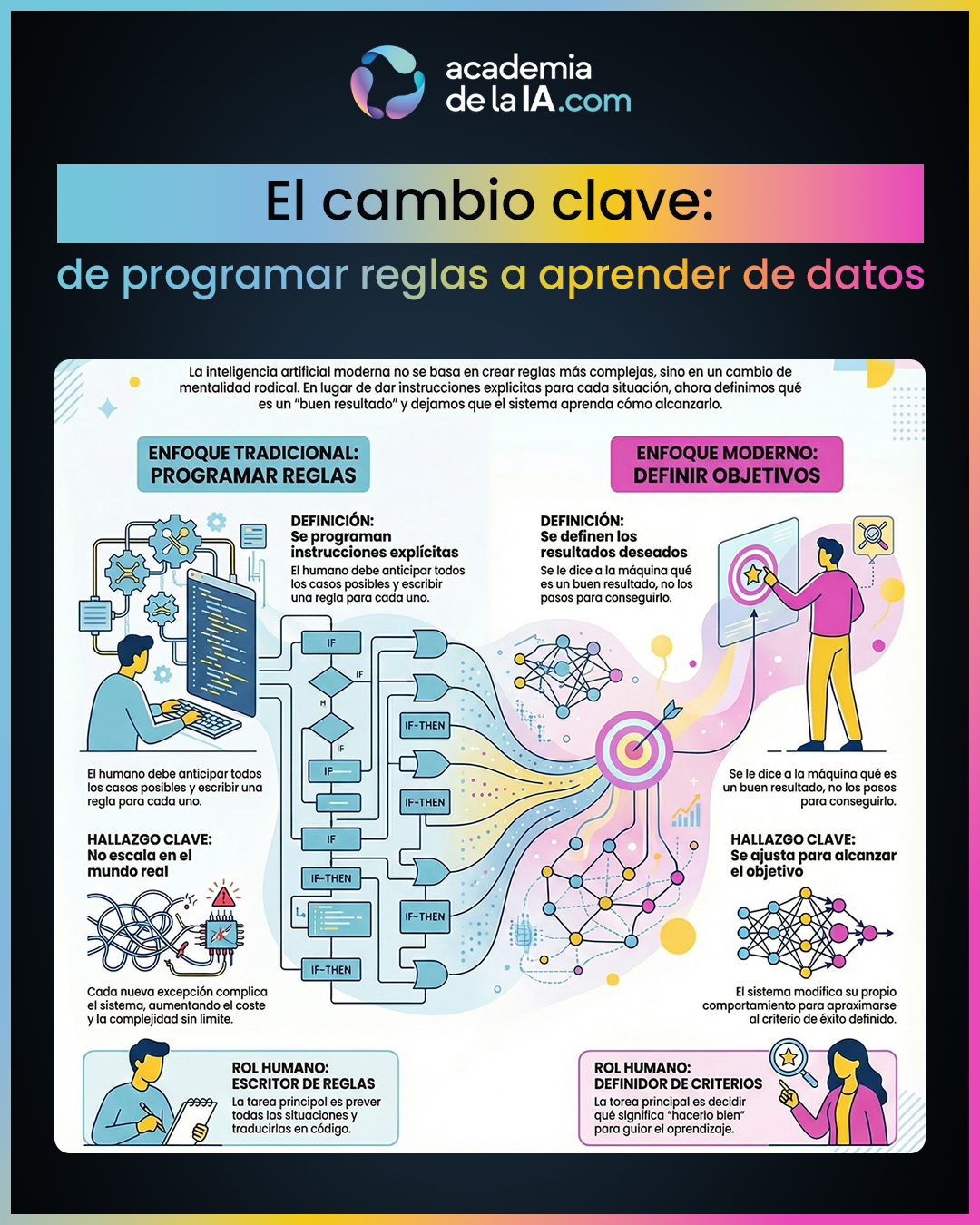
Hasta ahora, en el curso hemos entendido qué es la inteligencia artificial, por qué surge y qué tipo de inteligencia es la que estamos utilizando hoy. Con ese marco claro, este capítulo introduce el giro conceptual que hace posible la IA moderna: abandonar la idea de escribir reglas exhaustivas para describir el mundo.
Durante décadas, el enfoque dominante del software consistía en anticipar casos y traducirlos en instrucciones explícitas. Ese enfoque funciona bien cuando el problema está acotado y las situaciones posibles son limitadas. Pero el mundo real no funciona así: los casos se multiplican, aparecen excepciones inesperadas y el esfuerzo por mantener reglas crece sin límite. Cada nueva regla no cierra el problema, lo complica.
La IA moderna aparece cuando se asume ese límite y se adopta una idea distinta: en lugar de decirle a la máquina cómo actuar en cada caso, se le indica qué consideramos un buen resultado. A partir de ahí, el sistema ajusta su comportamiento buscando aproximarse a ese objetivo. No seguimos escribiendo soluciones; definimos criterios.
Este cambio transforma también el papel humano. Ya no se trata de prever todas las situaciones posibles, sino de definir qué significa hacerlo bien. El foco pasa de las instrucciones a los objetivos, y de las reglas al ajuste. Este capítulo no entra en cómo se implementa técnicamente ese ajuste, sino en por qué este cambio de mentalidad marca un antes y un después en la historia de la inteligencia artificial.
Este giro conceptual abre la puerta a una pregunta inevitable, que será el centro del siguiente capítulo: si una máquina no sigue reglas escritas… qué significa entonces que “aprenda”.
Aprendizaje de este capítulo
- La IA moderna no surge de reglas más sofisticadas, sino de abandonar la idea de que el mundo puede describirse completamente mediante instrucciones explícitas. El límite no es técnico, es conceptual.
- Programar reglas implica anticipar todos los casos posibles. En problemas reales, ese enfoque no escala: cada regla nueva genera excepciones nuevas, aumentando el coste y la complejidad sin cerrar nunca el sistema.
- El cambio clave consiste en pasar de decirle a la máquina qué hacer a decirle qué resultado es bueno. El sistema no recibe soluciones, recibe objetivos y ajusta su comportamiento en función de ellos.
- Este enfoque introduce el concepto de ajuste progresivo: el comportamiento no está fijado de antemano, sino que se va modificando para aproximarse a un criterio definido externamente.
- El rol humano cambia de forma profunda: dejamos de ser escritores de reglas y pasamos a ser definidores de criterios de éxito, responsables de decidir qué significa “hacerlo bien”.
CAPÍTULO 7
Qué significa “aprender” en una máquina
Resumen del capítulo
Después de haber definido qué entendemos hoy por inteligencia artificial, este capítulo aborda una de las confusiones más habituales: asumir que todo lo que funciona de forma automática es IA. En la práctica, muchas de las soluciones que se presentan como inteligencia artificial pertenecen en realidad a capas anteriores de tecnología que siguen siendo muy valiosas, pero que no son lo mismo.
Aquí se establece una distinción clara entre tres niveles distintos. Por un lado, el software tradicional, basado en reglas explícitas escritas por personas: si ocurre X, el sistema hace Y. Es determinista y previsible, porque cada comportamiento está definido de antemano. Sobre ese software se construye la automatización, que no introduce inteligencia nueva, sino que encadena reglas y procesos para ahorrar tiempo, reducir errores y escalar tareas repetitivas. Puede ser muy sofisticada y extremadamente útil sin necesidad de ser IA.
La inteligencia artificial aparece cuando ese enfoque deja de ser viable. Cuando el número de casos posibles crece, cuando hay incertidumbre y cuando no podemos escribir reglas para todas las situaciones futuras, el sistema deja de operar como un flujo cerrado y empieza a comportarse de forma razonable ante lo no previsto. Este capítulo no entra en cómo se consigue ese comportamiento, sino en cómo reconocerlo desde fuera, para no confundir automatización avanzada con inteligencia artificial real.
Aprendizaje de este capítulo
- No todo lo automático es inteligencia artificial. Un sistema puede ejecutar tareas de forma autónoma y repetible sin incorporar ningún tipo de IA. Automatizar no es un paso inferior ni obsoleto: es una capa distinta con un propósito claro y muy eficaz cuando el problema está bien definido.
- El software tradicional se basa en reglas explícitas, escritas por personas y pensadas para cubrir todos los casos posibles. Funciona bien cuando el entorno es estable y previsible, pero se vuelve frágil y costoso de mantener cuando aparecen demasiadas excepciones.
- La automatización encadena reglas y procesos, creando flujos más complejos que ahorran trabajo humano. Aunque puede parecer “inteligente”, sigue dependiendo de caminos previamente definidos y no maneja bien lo inesperado.
- La inteligencia artificial aparece cuando las reglas no alcanzan. Si no puedes describir el comportamiento del sistema como un árbol completo de decisiones, y aun así responde de forma razonable ante casos nuevos, estás ante algo que ya pertenece al ámbito de la IA.
Distinguir estas capas ajusta expectativas y evita errores de uso. Comprender qué tipo de sistema tienes delante te permite valorarlo mejor, exigirle lo que realmente puede dar y no atribuirle capacidades —ni responsabilidades— que no tiene.



CAPÍTULO 8
Qué es el Machine Learning
Resumen del capítulo
Después de haber definido qué es la inteligencia artificial, por qué no se basa en reglas exhaustivas y qué significa realmente aprender en una máquina, todo ese marco necesita un nombre claro. Este capítulo introduce ese nombre: Machine Learning.
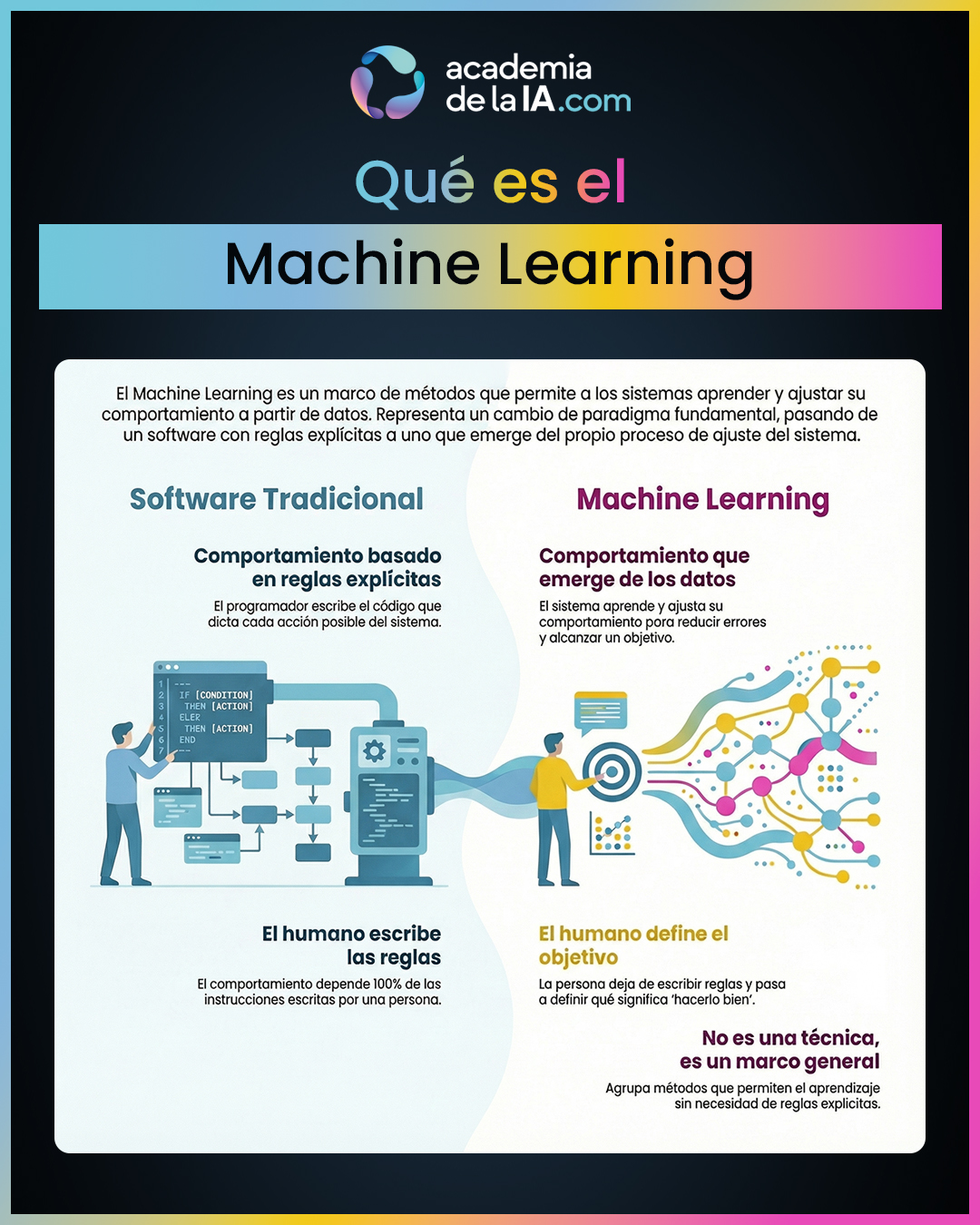
Machine Learning no es una técnica concreta ni un algoritmo específico. Es un marco general de métodos cuyo objetivo es permitir que un sistema aprenda a partir de datos, ajustando su comportamiento sin que un humano tenga que escribir reglas explícitas para cada caso posible. No describe “cómo” exacto se implementa algo, sino qué tipo de enfoque se está utilizando.
La idea central es sencilla: en lugar de decirle a la máquina qué hacer en cada situación, se le permite ajustar su comportamiento observando resultados y reduciendo error respecto a un objetivo. Esto conecta directamente con lo visto en el capítulo anterior: aprender como mejora progresiva del rendimiento, no como comprensión.
Este cambio supone un giro profundo respecto al software tradicional. Antes, el comportamiento del sistema dependía casi por completo de las reglas escritas por personas. Con Machine Learning, el comportamiento final emerge del proceso de ajuste del propio sistema, guiado por datos y criterios de éxito.
El capítulo también aclara qué no es Machine Learning, para evitar confusiones habituales. No es sinónimo de toda la inteligencia artificial, no es una caja mágica y no es un único método milagroso. Es el marco que hace posible que las máquinas aprendan sin reglas explícitas, con todas las implicaciones y límites que eso conlleva.
Este cierre deja preparado el terreno para el siguiente paso natural: entender que dentro de Machine Learning existen distintas formas de aprender, según el tipo de guía disponible.
Aprendizaje de este capítulo
- Machine Learning es un marco general, no una técnica concreta ni un algoritmo específico. Agrupa métodos cuyo objetivo es permitir aprendizaje sin reglas explícitas.
- Su función principal es hacer posible que un sistema ajuste su comportamiento a partir de datos, reduciendo error respecto a un objetivo definido externamente.
- Machine Learning no sustituye la definición humana de objetivos: el humano deja de escribir reglas, pero sigue definiendo qué significa hacerlo bien.
- No toda la IA es Machine Learning, ni todo Machine Learning es “inteligencia” en sentido amplio. Es una pieza clave, pero no el conjunto completo.
- El cambio de paradigma es estructural: se pasa de sistemas cuyo comportamiento depende de reglas escritas por personas a sistemas cuyo comportamiento se ajusta dinámicamente en función de resultados.
CAPÍTULO 9
Tipos de aprendizaje automático
Resumen del capítulo
Una vez definido qué es el Machine Learning como marco general, este capítulo introduce una distinción fundamental: no todas las máquinas aprenden bajo las mismas condiciones. La diferencia no está en la “inteligencia” del sistema, sino en el tipo de guía externa que recibe durante el proceso de ajuste.
El capítulo presenta las tres grandes familias de aprendizaje automático que se utilizan para clasificar prácticamente todos los sistemas actuales. Esta clasificación no pretende entrar en detalles técnicos, sino ofrecer un mapa conceptual claro que permita entender de qué hablamos cuando se dice que una máquina “aprende”.
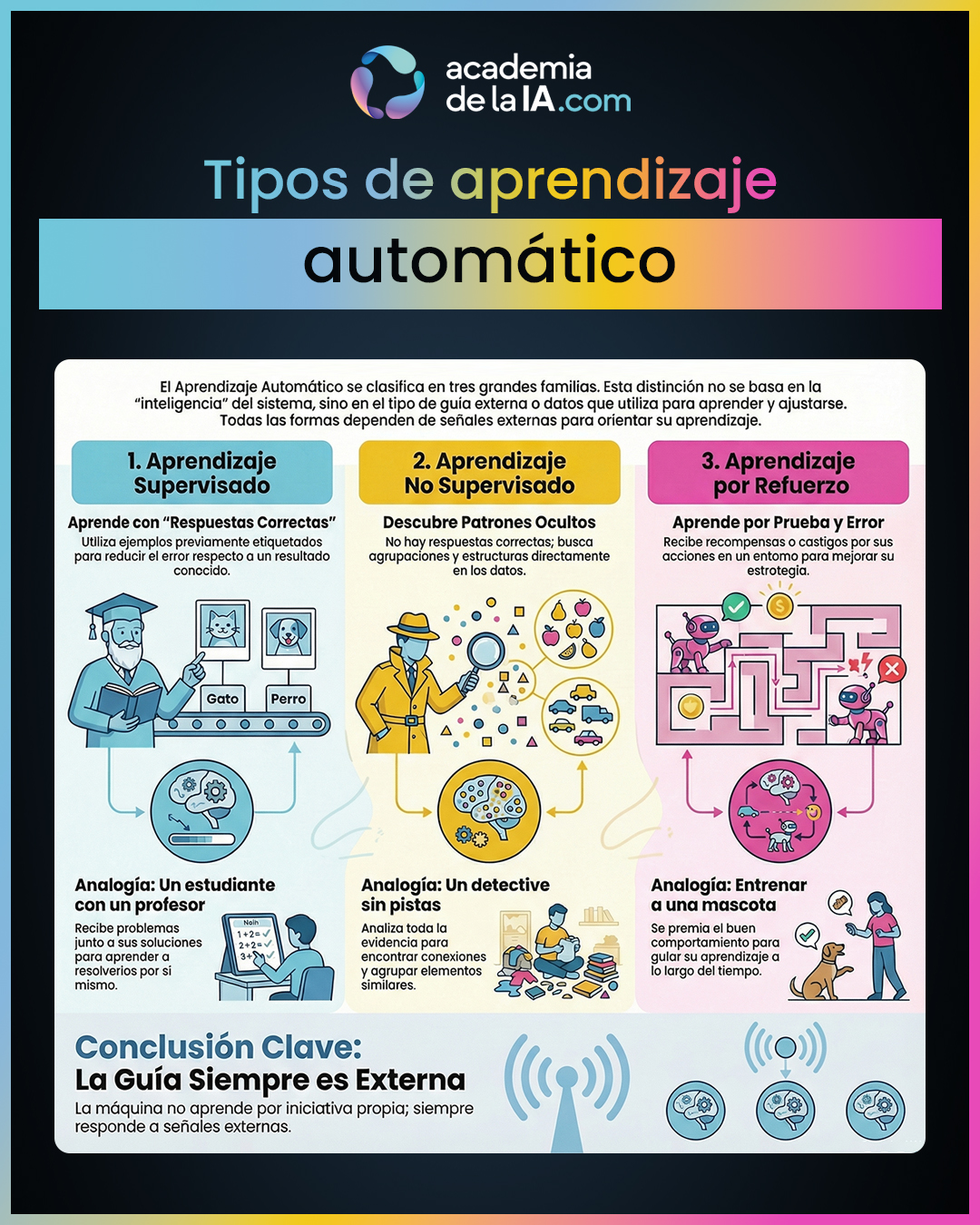
En el aprendizaje supervisado, el sistema aprende a partir de ejemplos acompañados de una referencia correcta. Alguien —una persona o un proceso— le indica qué resultados están bien y cuáles no. El sistema ajusta su comportamiento intentando reducir la diferencia entre lo que produce y lo que se considera correcto.
En el aprendizaje no supervisado, no existen respuestas correctas explícitas. El sistema no recibe etiquetas ni soluciones esperadas, sino que busca regularidades, agrupaciones o estructuras dentro de los datos disponibles. No hay un objetivo semántico claro, sino una exploración de patrones.
En el aprendizaje por refuerzo, el sistema aprende mediante prueba y error en interacción con un entorno. No se le dice qué está bien en cada caso, sino que recibe señales de recompensa o penalización según las consecuencias de sus acciones. El ajuste se guía por la acumulación de esas señales a lo largo del tiempo.
El capítulo cierra destacando la idea común que une a las tres formas de aprendizaje: todas dependen de una guía externa que orienta el ajuste del sistema. La máquina no decide qué aprender ni por qué; siempre responde a señales que vienen de fuera. Esa idea prepara el terreno para el siguiente capítulo, donde se analiza qué papel juegan los datos en todo este proceso.
Aprendizaje de este capítulo
- Existen tres grandes formas de aprendizaje automático: supervisado, no supervisado y por refuerzo. Esta clasificación se basa en el tipo de guía externa disponible, no en la complejidad del sistema.
- En el aprendizaje supervisado, el sistema ajusta su comportamiento usando ejemplos con respuestas correctas explícitas, intentando reducir el error respecto a esas referencias.
- En el aprendizaje no supervisado, no hay respuestas correctas ni objetivos explícitos: el sistema busca patrones y estructuras internas en los datos sin una guía directa sobre qué es “correcto”.
- En el aprendizaje por refuerzo, el ajuste se guía por recompensas y penalizaciones asociadas a las acciones del sistema, no por ejemplos correctos directos.
- En todos los casos, la máquina no aprende por iniciativa propia: siempre hay señales externas que guían el ajuste. La diferencia está en cómo se presentan esas señales, no en la existencia de una intención interna.



CAPÍTULO 10
Por qué los datos son más importantes que el código
Resumen del capítulo
Después de entender qué significa aprender en una máquina y cuáles son las distintas formas de aprendizaje automático, este capítulo introduce una idea clave que cambia por completo la forma de mirar la inteligencia artificial moderna: en muchos sistemas actuales, el código es menos determinante que los datos.
En el enfoque clásico del software, el comportamiento del sistema estaba definido casi por completo por las reglas escritas por los programadores. En el aprendizaje automático, ese papel se desplaza. El código establece el marco general, pero es la información que el sistema ve la que moldea realmente cómo se comporta. En ese sentido, los datos funcionan como una forma de experiencia acumulada: delimitan qué situaciones conoce el sistema y cómo responde ante ellas.
El capítulo explica que un sistema de IA no aprende “el mundo real”, sino el mundo que aparece reflejado en sus datos. Si los datos son incompletos, desbalanceados o sesgados, el comportamiento resultante también lo será. No porque el sistema tenga intención, sino porque no puede ir más allá de lo que ha observado. Por eso, añadir más datos no garantiza mejores resultados si esos datos no representan bien el problema que se quiere resolver.
También se subraya un límite fundamental: una IA no puede aprender aquello que no está presente en los datos. No puede compensar ausencias, corregir injusticias del mundo real ni aspirar a un ideal que no ha sido mostrado. El modelo refleja patrones observados, no principios abstractos de cómo “debería” ser la realidad.
Con este capítulo se cierra el Bloque 2. Ya no solo sabemos qué es aprender en una máquina y qué tipos de aprendizaje existen, sino también qué elemento condiciona de forma decisiva ese aprendizaje. Este cierre deja preparada la siguiente pregunta lógica: si los datos y el aprendizaje explican el comportamiento, ¿qué hay dentro de la máquina que permite procesarlos y generar resultados? Esa será la puerta de entrada al siguiente bloque.
Aprendizaje de este capítulo
- En la IA moderna, los datos actúan como experiencia acumulada: determinan qué patrones puede aprender el sistema y cómo se comporta ante situaciones nuevas.
- El código define el marco general, pero los datos condicionan profundamente las capacidades reales del sistema, incluyendo sus aciertos y sus limitaciones.
- Cantidad no equivale a calidad: grandes volúmenes de datos mal representados o sesgados producen comportamientos igualmente problemáticos.
- Un sistema de IA no puede aprender lo que no está presente en los datos; siempre refleja el mundo observado, no un ideal ni una realidad corregida.
- Comprender el papel central de los datos es clave para entender por qué la IA puede ser muy potente en algunos contextos y sorprendentemente frágil en otros.
¿Listo para el siguiente paso?
El conocimiento se construye capa por capa.
Continúa tu recorrido por los siguientes bloques, donde profundizarás en cómo funciona la IA, aprenderás a comunicarte con ella y desarrollarás criterio para un uso responsable.
